一、取得模型
方法一:登入 HuggingFace 向 Meta 申請存取權限
- 登入 HuggingFace 之後去 https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct 申請 meta-llama/Meta-Llama-3-8B-Instruct 的存取權限 (約一小時內會審核通過)
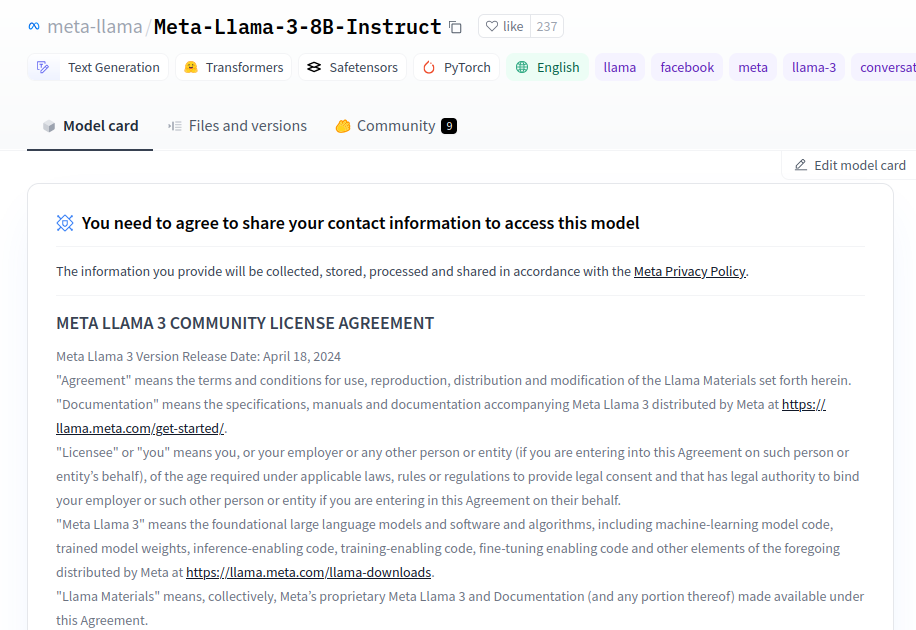
- 若出現如下圖的 “You have been granted access to this model” 字樣,即表示已取得模型存取權限,可以下載模型
- 如果要使用需要登入的模型,則需要此步驟設定HuggingFace Token,如果是無須登入即可存取的模型,則可直接跳過該步驟
來到 https://huggingface.co/settings/tokens?new_token=true
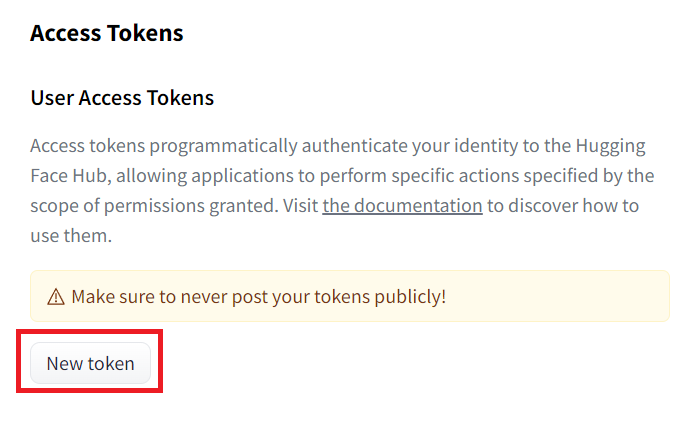
輸入你要的名稱
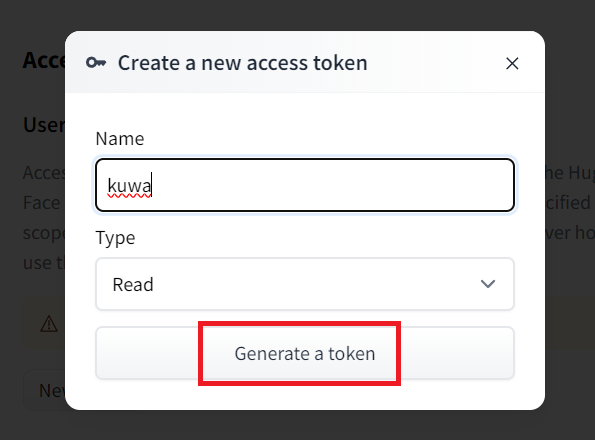
然後將此token保管好(不要透露給任何人知道)
方法二:免登入直接從 HuggingFace 第三方下載
- 如果不想登入HuggingFace的話,可以找第三方重新上傳的模型(名稱為Meta-Llama-3-8B-Instruct,無GGUF):
HuggingFace查詢: https://huggingface.co/models?search=Meta-Llama-3-8B-Instruct
例如NousResearch/Meta-Llama-3-8B-Instruct,記住名稱即可
二、Kuwa設定
方法一:使用指令啟動 Executor
-
使用以下指令即可啟動 Llama3 8B Instruct 的 Executor (存取代碼為
llama3-8b-instruct),<YOUR_HF_TOKEN>為前一步取得的 HuggingFace Token ,若是從第三方下載則留空。--model_path後面接的是 Huggingface hub 上的模型名稱,
取得模型方法一者:meta-llama/Meta-Llama-3-8B-Instructexport HUGGING_FACE_HUB_TOKEN=<YOUR_HF_TOKEN>
kuwa-executor huggingface --access_code llama3-8b-instruct --log debug --model_path meta-llama/Meta-Llama-3-8B-Instruct --stop "<|eot_id|>" --no_system_prompt取得模型方法二者:
NousResearch/Meta-Llama-3-8B-Instructexport HUGGING_FACE_HUB_TOKEN=
kuwa-executor huggingface --access_code llama3-8b-instruct --log debug --model_path NousResearch/Meta-Llama-3-8B-Instruct --stop "<|eot_id|>" --no_system_prompt -
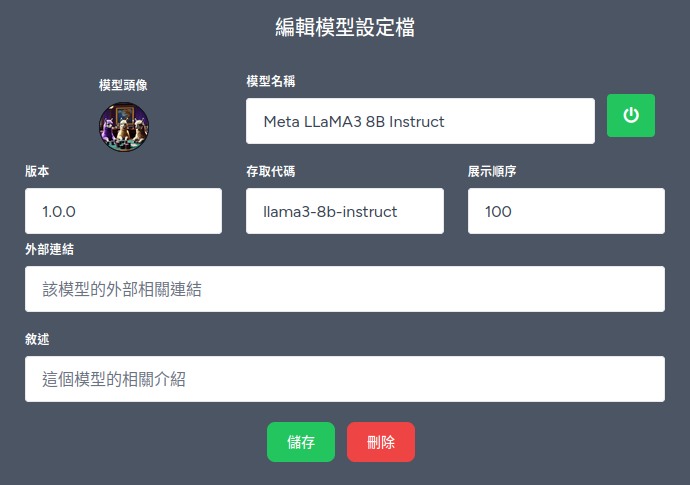
於網頁前端新增 Llama3 8B Instruct 的模型設定後,即可使用
方法二:使用 Docker 啟動 Executor
- 於
genai-os/docker/目錄下新增llama3.yaml並填入以下內容,若使用取得模型方法一者,須將command中的--model_path參數值改為meta-llama/Meta-Llama-3-8B-Instruct
services:
llama3-executor:
build:
context: ../
dockerfile: docker/executor/Dockerfile
image: kuwa-executor
environment:
EXECUTOR_TYPE: huggingface
EXECUTOR_ACCESS_CODE: llama3-8b-instruct
EXECUTOR_NAME: Meta Llama3 8B Instruct
# HUGGING_FACE_HUB_TOKEN: ${HUGGING_FACE_HUB_TOKEN}
depends_on:
- kernel
- multi-chat
command: ["--model_path", "NousResearch/Meta-Llama-3-8B-Instruct", "--no_system_prompt", "--stop", "<|eot_id|>"]
restart: unless-stopped
volumes: ["~/.cache/huggingface:/root/.cache/huggingface"]
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0']
capabilities: [gpu]
networks: ["backend"]
-
使用以下指令啟動新的 container (
<...>為舊有系統的 compose 檔案組合,舊有系統不須停止)sudo docker compose -f compose.yaml <...> -f llama3.yaml up --build -
出現如下圖的畫面即表示 Executor 執行成功

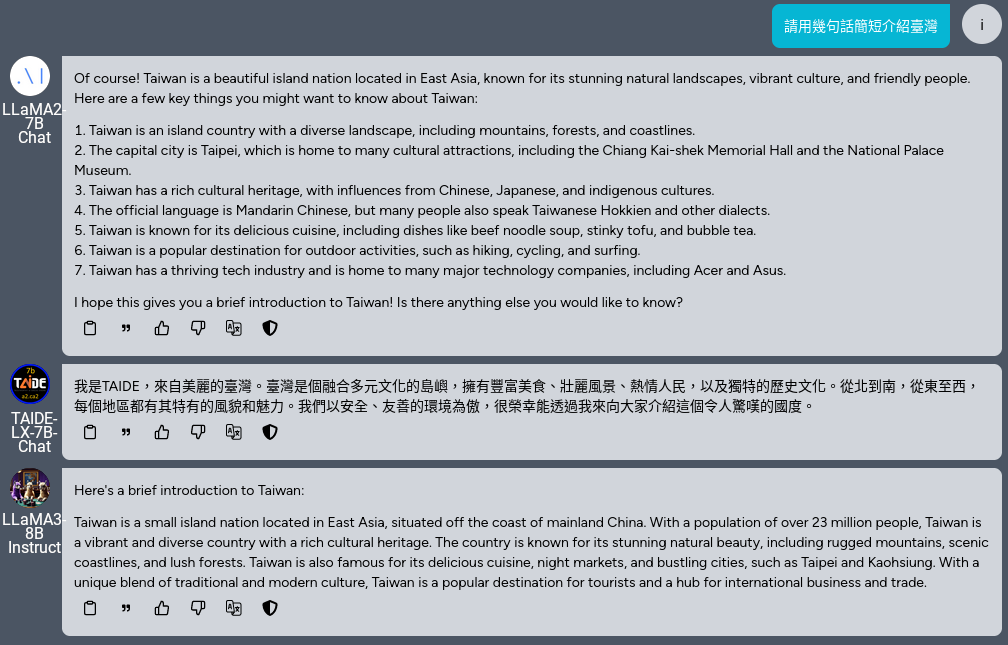
三、Kuwa 使用
- 請等模型下載完成後再登入 Kuwa,可以開始和 Llama3 聊天
- Llama3 預設喜歡講英文,可以透過「用此模型翻譯」功能透過模型本身將模型回應翻譯成中文

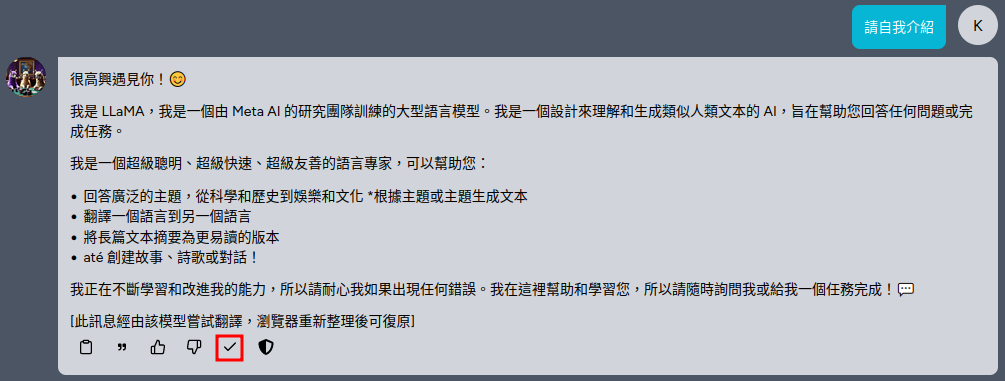
- 可透過群聊功能同時比較Llama3、Llama2 與 TAIDE-LX-7B-Chat 的回應