
Kuwa v0.3.1 初步支援了常見的視覺語言模型 (VLM), 這類模型不但可以輸入文字,還可以輸入圖片,並根據圖片內容回應使用者的指令。 本篇教學將帶您初步建立與使用 VLM。
VLM Executor 建置
Kuwa v0.3.1 擴充了原先的 Huggingface executor,使其能支援 VLM,
目前初步支援 Phi-3-Vision, LLaVA v1.5 與 LLaVA v1.6 等三種常見的 VLM,
以下以 LLaVA v1.6 為例。
Windows 版建置流程
參考先前的 Llama3建置教學,
"model path" 輸入 llava-hf/llava-v1.6-mistral-7b-hf,"Arguments to use" 留白即可。
Docker 版建置流程
參考以下 Docker compose設定
services:
llava-v1.6-executor:
build:
context: ../../
dockerfile: docker/executor/Dockerfile
image: kuwa-executor
environment:
EXECUTOR_TYPE: huggingface
EXECUTOR_ACCESS_CODE: llava-v1.6-7b
EXECUTOR_NAME: LLaVA v1.6 7B
# HUGGING_FACE_HUB_TOKEN: ${HUGGING_FACE_HUB_TOKEN}
depends_on:
- kernel
- multi-chat
command: ["--model_path", "llava-hf/llava-v1.6-mistral-7b-hf", "--log", "debug"]
restart: unless-stopped
volumes: ["~/.cache/huggingface:/root/.cache/huggingface"]
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0']
capabilities: [gpu]
networks: ["backend"]
VLM 使用
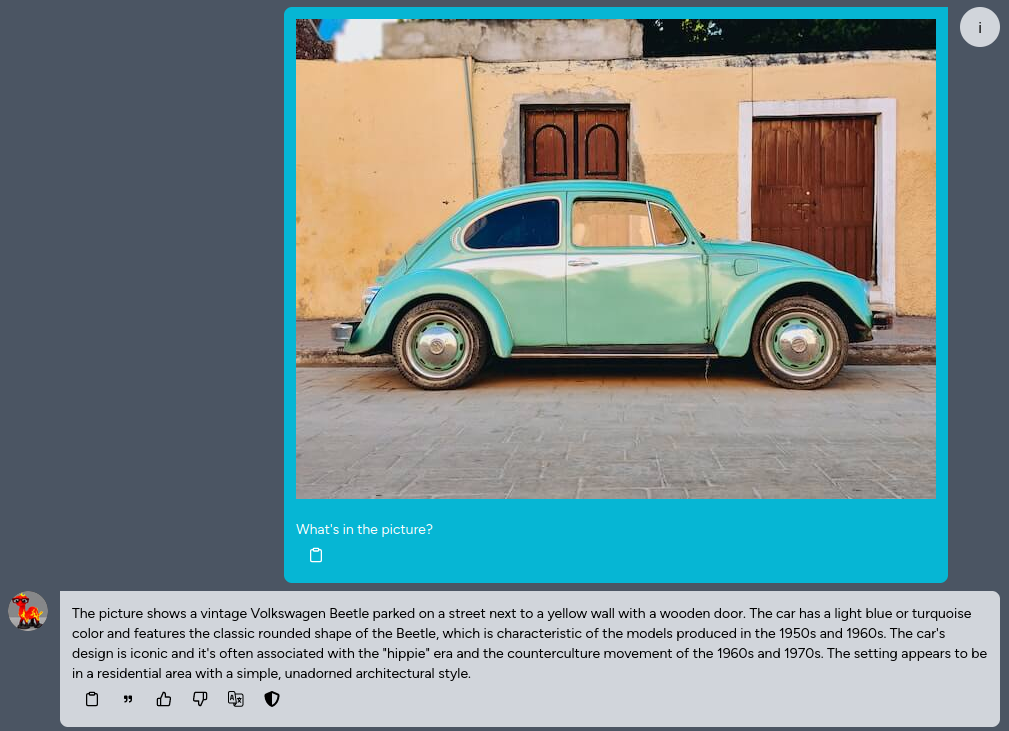
您可以上傳一張圖片並對這張圖片進行提問,或是要求模型辨識上面的文字。