
Kuwa v0.3.1 加入了基於 Whisper 語音辨識模型的 Kuwa Speech Recognizer, 可以透過上傳錄音檔來產生逐字稿,支援時間戳記以及語者標示。
已知問題與限制
硬體需求
預設使用 Whisper medium 模型並關閉語者標示功能,若跑在GPU上所消耗 VRAM 如下表所示。
| 模型名稱 | 參數量 | VRAM需求 | 相對辨識速度 |
|---|---|---|---|
| tiny | 39 M | ~1 GB | ~32x |
| base | 74 M | ~1 GB | ~16x |
| small | 244 M | ~2 GB | ~6x |
| medium | 769 M | ~5 GB | ~2x |
| large | 1550 M | ~10 GB | 1x |
| pyannote/speaker-diarization-3.1 (語者辨識) | - | ~3GB | - |
已知限制
- 目前無法自動偵測輸入語言,須手動指定
- 目前語者辨識模組因為多��行程的關係,導致每次都會重新載入模型,拉長響應時間
- 多語者同時講話時容易誤判內容
建置 Whisper Executor
前置步驟
若您需要語者辨識功能的話,請參考以下步驟取得語者辨識模型的授權:
- 同意 pyannote/segmentation-3.0 與 pyannote/speaker-diarization-3.1 的授權條款
- 參考各版本的指南加入 HuggingFace access token
Windows 版啟動步驟
Windows 版預設應會自動執行 Whisper Executor,若沒有執行的話請按照以下步驟執行:
- 雙��擊
C:\kuwa\GenAI OS\windows\executors\download.bat,下載 Whisper Model,如有需要語者辨識功能可以一併下載Diarization Model - 雙擊
C:\kuwa\GenAI OS\windows\executors\whisper\init.bat以產生相關執行設定 - 重開 Kuwa,或是在 Kuwa 的終端機視窗輸入
reload重新載入 Executor - 一個名為 Whisper 的 Executor 應會被加入您的 Kuwa 系統中
Docker 版啟動步驟
Kuwa Speech Recognizer 的 Docker compose 設定檔位於 docker/compose/whisper.yaml,可以參考以下步驟啟動:
- 將
"whisper"加入docker/run.sh中的 confs 陣列 (若無這個檔案則從 run.sh.sample 複製) - 執行
docker/run.sh up --build --remove-orphans --force-recreate - 一個名為 Whisper 的 Executor 應會被加入您的 Kuwa 系統中
使用 Whisper
語音轉逐字搞
可以上傳一個語音檔來產生逐字搞,預設辨識語言為英文
![]()
新增一個 Bot,並指定參數PARAMETER whisper_language zh 就能產生中文或其他語言的逐字稿
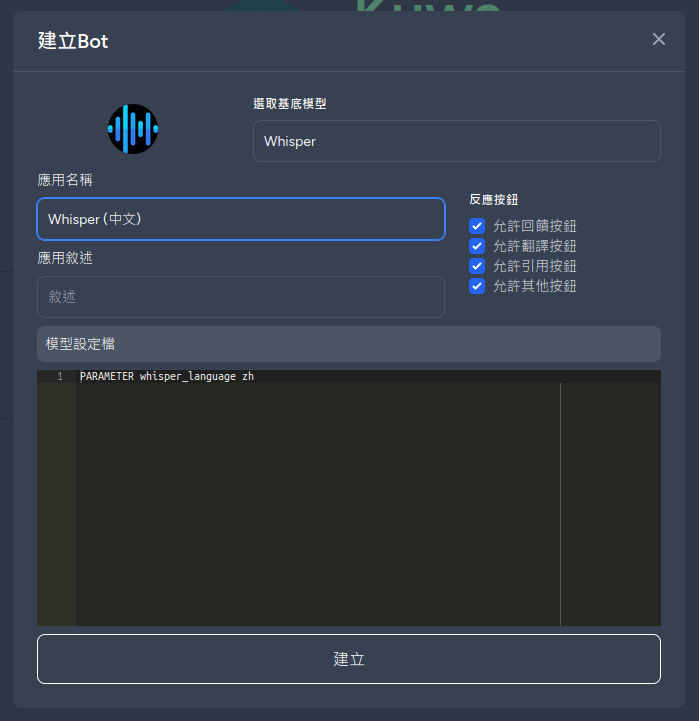
![]()
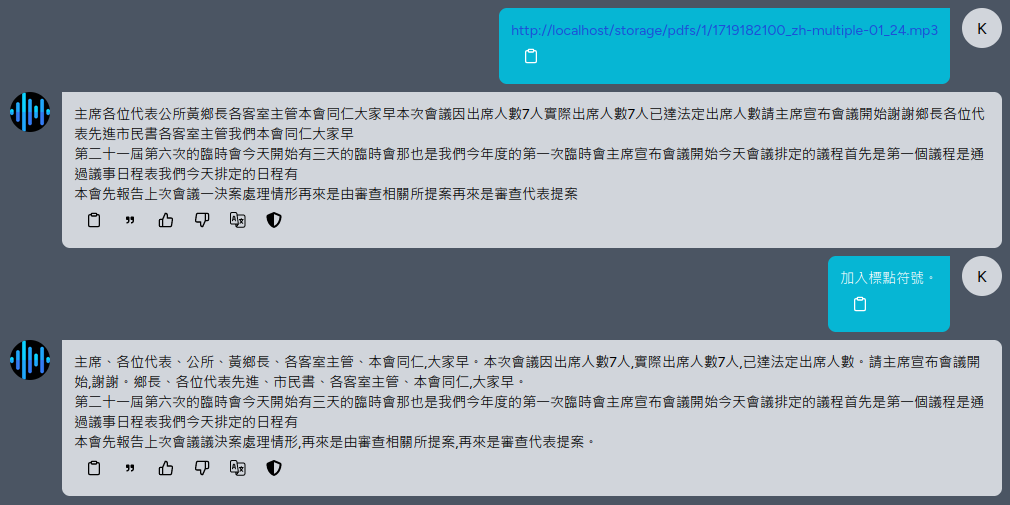
Whisper 模型在中文時預設不愛輸出標點符號,可以透過 User prompt 或是 System prompt 影響模型產生結果。
逐字稿時間戳記
在 Bot 的設定檔中新增參數PARAMETER whisper_enable_timestamp True即可啟用逐字稿的時間戳記
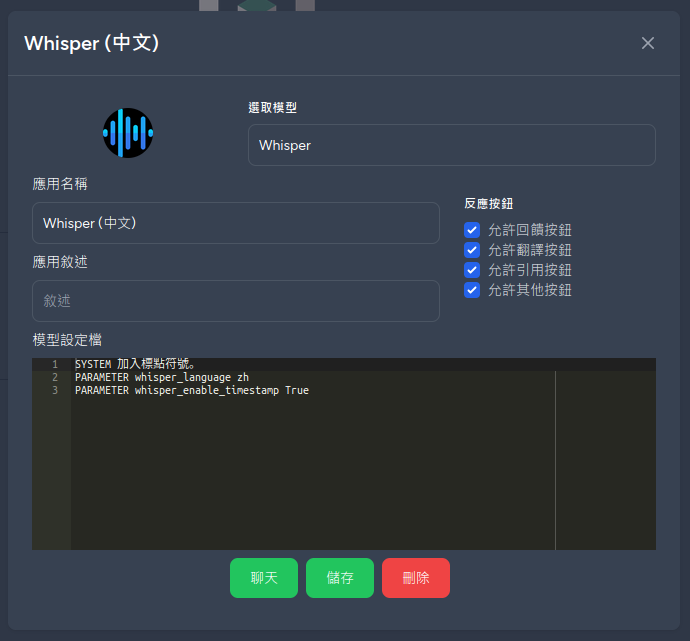

上面範例中,使用者輸入"."只是為了讓模型取用先前上傳的錄音檔,記得將聊天模式選為"連貫問答"。
語者辨識
一樣在 Bot 的設定檔中新增參數PARAMETER whisper_enable_diarization True即可啟用語者辨識及標注功能
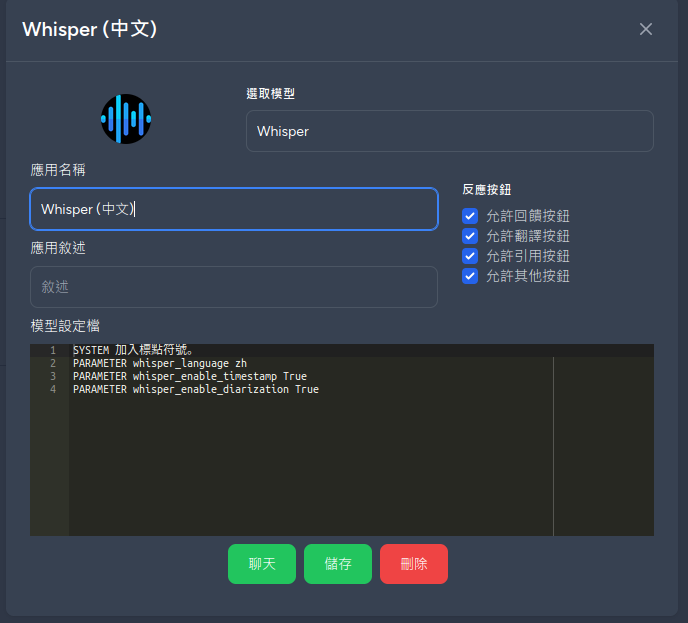
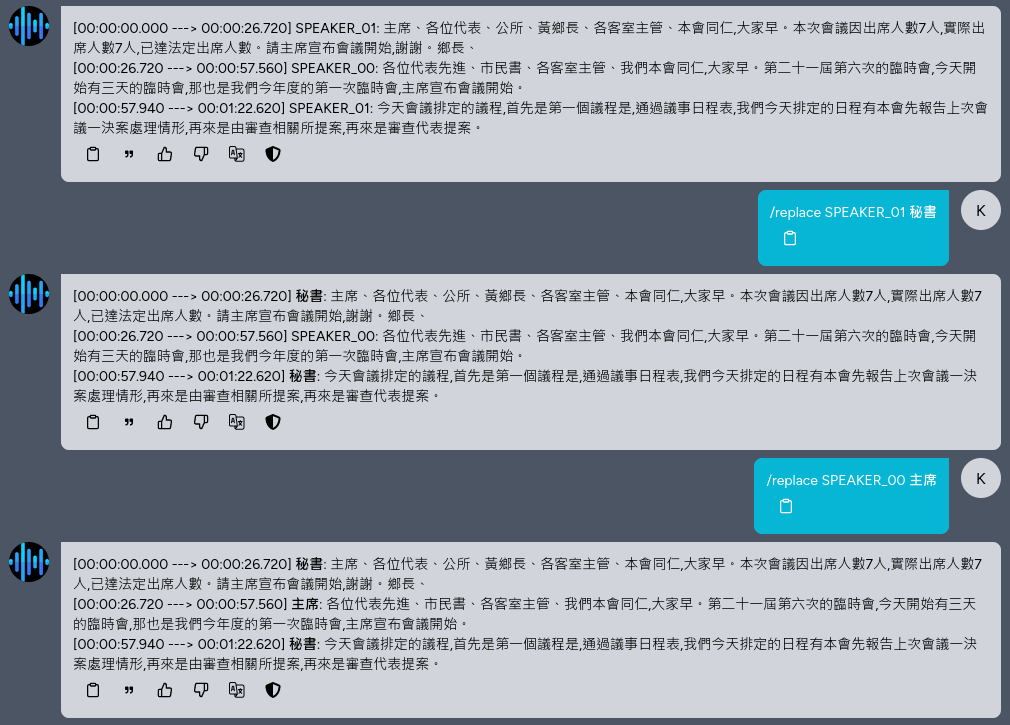
指令 /replace <pattern> <repl> 可以使用正則表達式置換辨識結果,可以替換語者名字或是重複辨識錯誤的字詞
指令 /speakers <n> 可以指定有幾個語者,預設會自動偵測,但可能會有偏誤,可使用這個指令修正
完整設定說明
Bot 可設定參數如下,完整說明可以參考 ganai-os/src/executor/speech_recognition/README_TW.md
SYSTEM "加入標點符號。" #Custom vocabulary or prompting
PARAMETER whisper_model medium #Model name. Choses: large-v1, large-v2, large-v3, medium, base, small, tiny
PARAMETER whisper_enable_timestamp True #Prepend the text a timestamp
PARAMETER whisper_enable_diarization True #Label the speaker
PARAMETER whisper_diar_thold_sec 2 #Time before speakers are tagged in paragraphs that are longer than. (in seconds)
PARAMETER whisper_language zh #The language of the audio
PARAMETER whisper_n_threads None #Number of threads to allocate for the inference. default to min(4, available hardware_concurrency)
PARAMETER whisper_n_max_text_ctx 16384 #max tokens to use from past text as prompt for the decoder
PARAMETER whisper_offset_ms 0 #start offset in ms
PARAMETER whisper_duration_ms 0 #audio duration to process in ms
PARAMETER whisper_translate False #whether to translate the audio to English
PARAMETER whisper_no_context False #do not use past transcription (if any) as initial prompt for the decoder
PARAMETER whisper_single_segment False #force single segment output (useful for streaming)
PARAMETER whisper_print_special False #print special tokens (e.g. <SOT>, <EOT>, <BEG>, etc.)
PARAMETER whisper_print_progress True #print progress information
PARAMETER whisper_print_realtime False #print results from within whisper.cpp (avoid it, use callback instead)
PARAMETER whisper_print_timestamps True #print timestamps for each text segment when printing realtime
PARAMETER whisper_token_timestamps False #enable token-level timestamps
PARAMETER whisper_thold_pt 0.01 #timestamp token probability threshold (~0.01)
PARAMETER whisper_thold_ptsum 0.01 #timestamp token sum probability threshold (~0.01)
PARAMETER whisper_max_len 0 #max segment length in characters
PARAMETER whisper_split_on_word False #split on word rather than on token (when used with max_len)
PARAMETER whisper_max_tokens 0 #max tokens per segment (0 = no limit)
PARAMETER whisper_speed_up False #speed-up the audio by 2x using Phase Vocoder
PARAMETER whisper_audio_ctx 0 #overwrite the audio context size (0 = use default)
PARAMETER whisper_initial_prompt None #Initial prompt, these are prepended to any existing text context from a previous call
PARAMETER whisper_prompt_tokens None #tokens to provide to the whisper decoder as initial prompt
PARAMETER whisper_prompt_n_tokens 0 #tokens to provide to the whisper decoder as initial prompt
PARAMETER whisper_suppress_blank True #common decoding parameters
PARAMETER whisper_suppress_non_speech_tokens False #common decoding parameters
PARAMETER whisper_temperature 0.0 #initial decoding temperature
PARAMETER whisper_max_initial_ts 1.0 #max_initial_ts
PARAMETER whisper_length_penalty -1.0 #length_penalty
PARAMETER whisper_temperature_inc 0.2 #temperature_inc
PARAMETER whisper_entropy_thold 2.4 #similar to OpenAI's "compression_ratio_threshold"
PARAMETER whisper_logprob_thold -1.0 #logprob_thold
PARAMETER whisper_no_speech_thold 0.6 #no_speech_thold